What can we uncover by taking a dataset with potential signs of bipolar disorder and apply machine learning algorithms to identify patterns in the language. Could we detect behaviorial changes or shifts in mood?
Summary
My capstone project was centered around exploring Natural Language Processing tools and how to apply that in the realm of mental health and detecting bipolar tendencies.
Data
The dataset used was Kanye West lyrics across his entire discography. I wanted to determine if there were consistent groups that can be identified and if these changed over time. Significant time was spent in collecting each song and cleaning the text of each song into a usable corpus. Tasks include removing stop words, lemmatization, and lyric attribute removal using regex.
Models
Models were constructed for three main areas: Word Similarity, Topic Modeling, and Sequential Topic Modeling.
Word Similarity - Word2Vec
To better understand the linguistic contexts of words used in Kanye’s lyrics, I used a Word2Vec model to understand the words most similar to the most common words in certain topics. This help me identify areas to focus on and words most strongly associated with describing common themes.
Topic Modeling - Latent Dirichlet Allocation (LDA) and Non-negative Matrix Factorization (NMF)
Five topics were able to be generated that classified each of Kanye’s song into a different type based on vocabulary. The total number of topics was selected by evaluating the coherence score.
Sequential Topic Modeling
Finally, after identifying key words to review, I generated a sequential topic model that grouped topics across years to determine changes in vocabulary over time.
Takeaway
Unsupervised learning can provide useful tools in creating labels and generating additional features that may not be apparent at first. Uncovering trends and tendencies by using machine learning algorithms
Background
Kanye West is one of the most controversial public figures over the last decade and recently has been scrutinized for his views on politics and Trump. This has led many to view his actions as something to joke about or just plainly being dismissed as crazy. However, on his latest album ye, he openly states on the cover “ I hate being Bi-Polar, its awesome” and writes about bipolar disorder being his superpower on the track Yikes.
While behavior that is intended to hurt people is not excusable, the reality is bipolar disorder affects 6.86 million U.S. adults annually and is often overlooked since it is a misunderstood mental health condition. Commonly misdiagnosed or treatment being avoided all together due to the stigma surrounding bipolar disorder, getting the correct treatment to patients is still a hurdle preventing many from getting the help they need.
Bipolar Disorder
So what is Bipolar Disorder? The NIH defines bipolar disorder as being characterized by dramatic shifts in mood, energy, and activity levels that affect a person’s ability to carry out day-to-day tasks. These shifts in mood and energy levels are more severe than the normal ups and downs that are experienced by everyone.
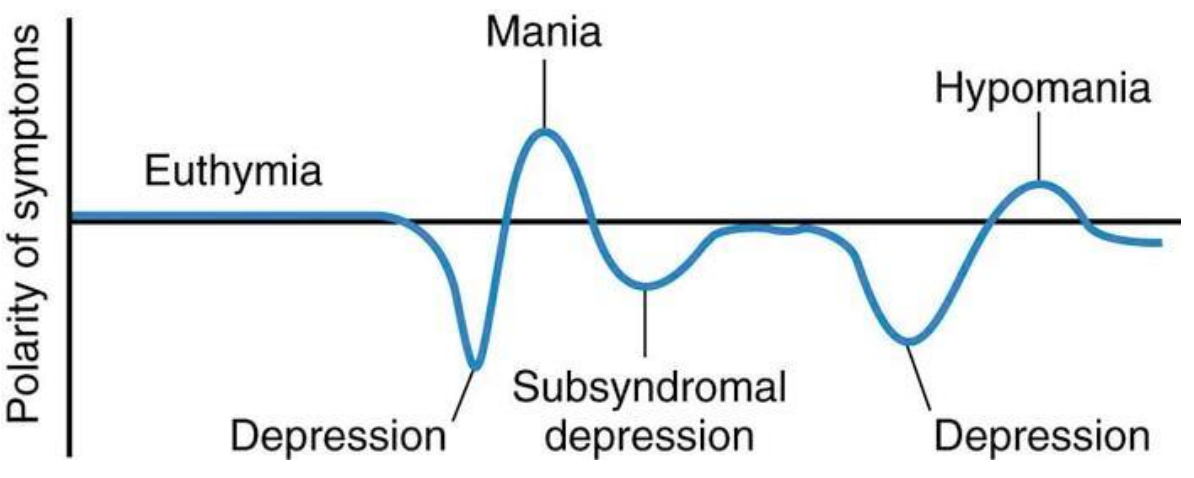
Knowing first hand the impact of living with bipolar disorder can have on your personal, financial, and everyday life, the potential of filling in this gap drew me to work on this subject. To close out my time at General Assembly, I wanted my capstone project to center on exploring if it was possible to create tools that can help predict and assist those with bipolar disorder before the onset of the more severe aspects of manic or depressive episodes and help them seek primary care.
Problem Statement
Using Machine Learning, what can we learn about how Kanye’s behavior and mental state has changed over time and can this be used to build models that can help predict bipolar episodes?
Data
Obtain the Data
In order to build out the data to look for changes over time, I collected as much data as I could that would give insight into what Kanye was thinking. This centered on the two areas where he shares his most revealing personal thoughts: _his lyrics and on Twitter.
First, I collected Kanye’s lyric data across all his songs.
1. Find a source for lyrics and create a function to access API for each song
My preference was to use a reliable API for lyrics to be able to collect all of Kanye’s song. I started by searching for possible APIs and settled on using Orion Apieseed lyric API. This API allowed to search by song and artist and returned the lyrics for each song. To use this, I just needed to generate a list of each of Kanye’s song.
url = "https://orion.apiseeds.com/api/music/lyric/" + artist + "/" + song + "?apikey=" + orion_keys['api_key']
2. Create a song list of Kanye’s body of work
To generate a full list of Kanye’s discography, I wanted to use the most consistent and full reference of work available from him. Spotify was the obvious choice and fortunately, there was Spotify wrapper available that allowed accessing using a Python library relatively easy. To access each song, I first had to look up each of Kanye’s album using the album id used by Spotify and then extract from the returned dictionary the song name of each entry.
from spotipy import Spotify
from spotipy.oauth2 import SpotifyClientCredentials
# Kanye's Spoitfy id
Kanye_spotify_id = '5K4W6rqBFWDnAN6FQUkS6x'
album_dict = sp.artist_albums(Kanye_spotify_id,country='US')
3. Collect lyrics
Once a full list of Kanye’s song was made, I could pass the list into a function to collect the lyrics from Orion Apiseed. After starting extracting lyrics, it became quite clear there was an issue since I was getting quite a bit of 404’s from individual requests. What was occurring was a mismatch in the song title with what was available in the Orion API. This was either due to:
A) slight variation in the song title between Orion and Spotify or B) Orion not having the song in their API.
To get around this issue, I ended up scraping the Genius lyric site for any remaining songs I was not able to get from Orion Apiseed.
Discography Summary
12 Albums
128 Unique Songs
62,648 Total Words Used
| Albums | Singles |
|---|---|
| KIDS SEE GHOSTS | I Love It |
| ye | XTCY |
| The Life Of Pablo | Lift Yourself |
| Yeezus | |
| My Beautiful Dark Twisted Fantasy | |
| 808s & Heartbreak | |
| Graduation | |
| Late Registration | |
| The College Dropout |
Text Cleaning
Note: WORDS USED IN LYRICS WERE NOT FILTERED OR CENSORED, SOME EXPLICIT CONTENT AHEAD
To feed lyrics into the various models I used, significant time was spent on cleaning and making the data that was collected useable. To do this, several steps to properly clean the data were taken:
1. Prep text into corpus
- Regex: Some lyric data also contains a reference to song structure (i.e. name of collaborating artist) and needed to be removed since it wasn’t essential to the analysis. This was completed by filtering words through regex using
r"\[[^\]]*\]"as the sorting method. - Stop Words: Stop word were removed and I experimented using the starting list from either
NLTKandsklearnenglish words since they had different totals to start with. Additional words were added manually based on what was seen such as song fillers (‘uuuuhhh, ‘ooooohhs’). - Lemmatization: Finally the words were passed through a lemmatization function to reduce plural words to their singular word.
# Function to clean text
def clean_text(song):
clean_text_step = [song.splitlines()]
for song in clean_text_step:
clean_song = []
for line in song:
if line != '':
line = re.sub(r'[^\w\s]','',line) # Removes Punctuation
line_2 = [lemmatizer.lemmatize(word) for word in line.lower().split() if word not in stop] # Stem words (remove plural)
clean_song.append(line_2)
else:
pass
return clean_song
2. Vectorize words for use in model
To separate words in preparation for topic modeling or classification, the cleaned lyrics corpus was prepared in both a count vectorizer and a TF-IDF vectorizer. Both were used to feed words into the LDA and NMF models and analyzed for effectiveness.
- Count Vectorizer: Total Count Frequency
- TFIDF Vectorizer: Term Frequency for all Observations
Unfortunately, Kanye decided to delete his Twitter and Instagram account during the middle of my data collection and I could not include in my project based on the timeline I was working with.
Models
After the data was processed, it was ready to be used across different types of model to try and classify observations into coherent groups. With unsupervised learning, it is extremely difficult to work on grouping data into clusters that actually make sense. This involves a lot of fine tuning and exploration to try and pinpoint what is the best at summarizing into meaningful sets.
To do this, I attempted two different models to group songs into topics:
Topic Modeling
- LDA (Latent Dirichlet allocation) - Statistics Based
- NMF (Non-negative Matrix Factorization) - Linear Algebra
LDA provided the most interpretable results with the count vectorized lyric data for the word groupings that were being returned.
But how many topics to go with? Similar to selecting the number of clusters to use in k-Means, finding the right balance here requires using several different possible evaluation methods. I chose to use a metric called Coherence Score to help in this process. The coherence score can be calculated across different topic numbers and compare to see which provide the right fidelity to the level you are looking for. My intention was to allocate songs into as many topics as possible that were descriptive but so much that isolated one song per topic. On the flip side, selecting too few topics lumps almost all songs into general groups where uniqueness cannot be easily defined.
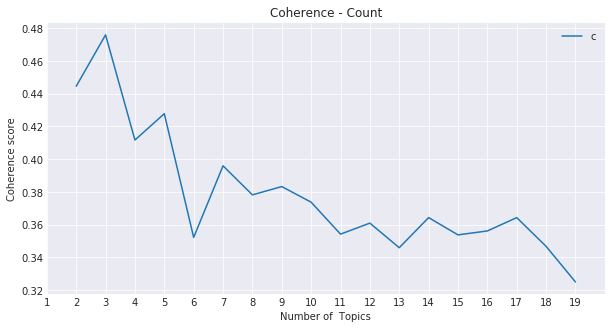
I choose to use a five-topic split since it provided a balance in scoring well for coherence and I could interpret the top words into meaningful groups. Listed below were the topics I settled on:
Topics
- Public Persona - Songs about being in the spotlight and fame
- Speak Ye Truth - Kanye singing about what he believes and the truth he wants to speak
- Broke /Women/ Money - Songs about not having and having money and all his different experiences with women in his life
- Life - General topic about the issues he has faced in life and handling the ups and downs
- Make Right/ Legacy - Ye’s reflecting on his legacy and the trying to make things right for the mistakes he has realized he has made
Each song can be labeled as most likely belong to a particular topic. Most notable, I believe, was more songs being in the topic group Life among his more recent work than in his breakout albums where Money and Legacy appeared to dominate.
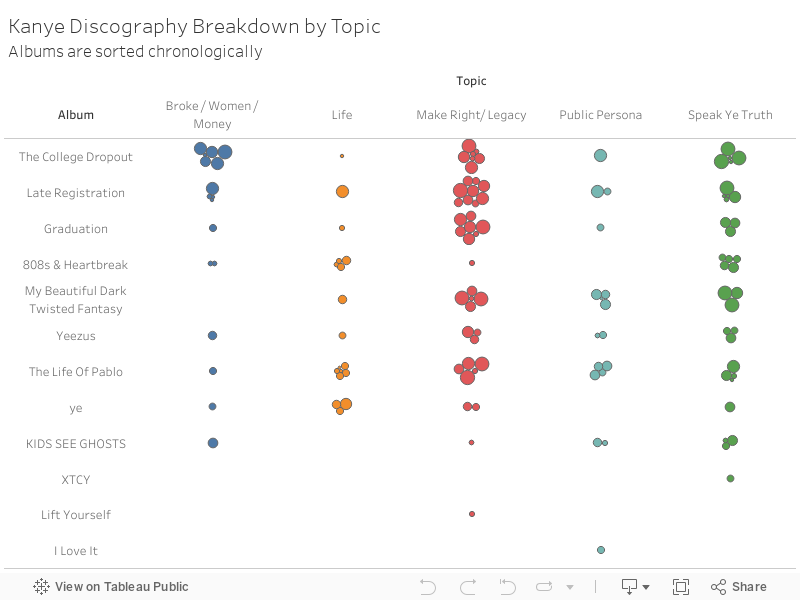
Each song is given a probability of belonging to a particular topic. As an additional means of evaluating topic coherence, I reviewed how well the most probabilist song from each topic belonged there. Overall, this returned solid results.
Highest Probability Song For Each Topic
0.9954962574881103
['All of the Lights']
['My Beautiful Dark Twisted Fantasy']
Public Persona
0.9988632784766937
['Last Call']
['The College Dropout']
Speak Ye Truth
0.9966221495074559
['The New Workout Plan']
['The College Dropout']
Broke / Women / Money
0.9955740231167477
['Drive Slow']
['Late Registration']
Life
0.9966283076899758
['Touch the Sky']
['Late Registration']
Make Right/ Legacy
Word Similarity
Topic grouping was just the beginning of the analysis and I wanted to bring in the ability to group words by similarity. This can be a beneficial tool in understanding how one uses diction and uses word association. Using a modeling method called Word2Vec, each word is given a directional vector and words most similar to it will be aligned along the same direction. This is done on a multidimensional plane and difficult to interpret but to help us visualize the model outputs I put them into a t-SNE plot to reorient onto a 2-D space.
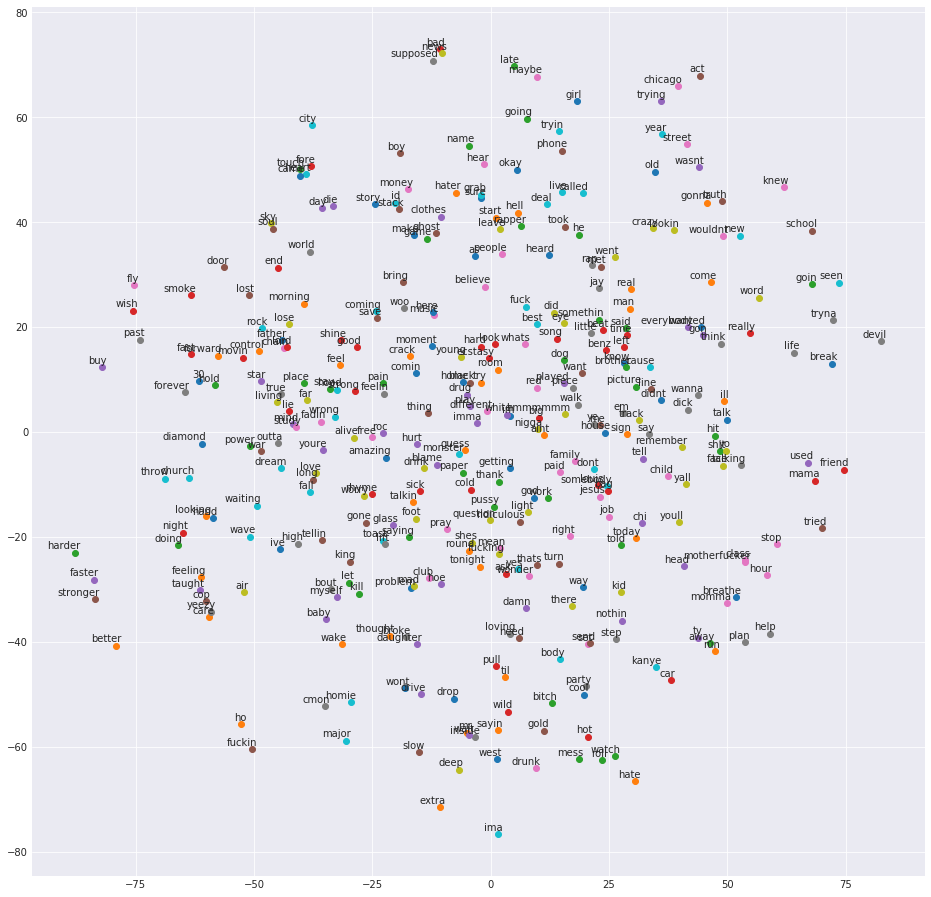
After the model was compiled, I wanted to isolate particular words that appeared frequently and understand what other similar words he associated with it. I started with Love:
Most Similar to: Love
[('fadin', 0.5092264413833618),
('mistake', 0.49861404299736023),
('wake', 0.46998417377471924),
('ho', 0.4642098546028137),
('myself', 0.42317628860473633),
('blame', 0.3949402868747711),
('fuckin', 0.381166934967041),
('walk', 0.38080090284347534),
('hate', 0.38067206740379333),
('save', 0.37218549847602844)]
A mix of positive and negative terms here is not surprising considering how complicated love is…
Next up was the word Myself since it appeared next to love and was fairly frequent:
Most Similar to: Myself
[('bed', 0.5850050449371338),
('killing', 0.5635855793952942),
('killed', 0.5398204326629639),
('dawg', 0.5226340293884277),
('loving', 0.5117295384407043),
('wake', 0.5074575543403625),
('hood', 0.5013218522071838),
('favorite', 0.4675023555755615),
('door', 0.4619908332824707),
('catch', 0.44258543848991394)]
Not something you would like to see associate next to the term myself is anything referencing killing. This type of model could potentially reveal someone commonly making references that could lead to harm coming to themselves or others.
Sequential Topic Model
Back to the core of our question regarding behavior changes over time, incorporating changes in topics over time a period seemed the most appropriate for detecting changes.
To process the model, I grouped songs by year of release to create a chronological evaluation group. Then, I tuned parameters in order to create the proper amount of sensitivity in vocabulary changes across topics that could be detected. This was done by adjusting a parameter called chain variance.
Visualization was key to understanding the output of the sequential topic model, so using Plotly provided an interactive platform within my Jupyter Notebook to conduct my analysis.
In exploring the model outputs, I picked up on the same word ‘myself’ being used and contextually what other words were included in that topic over time. The two charts below show the probability of certain words changing overtime along certain themes. Certain words were less used while others became more likely to appear. If words signaling troubling behavior or thoughts can be flagged, then treatment plans can be built around the needs of the patient at that time.
Changes Over Time
Language usage between ‘dead’ and ‘myself’ has changed over time between 2006 to 2016.
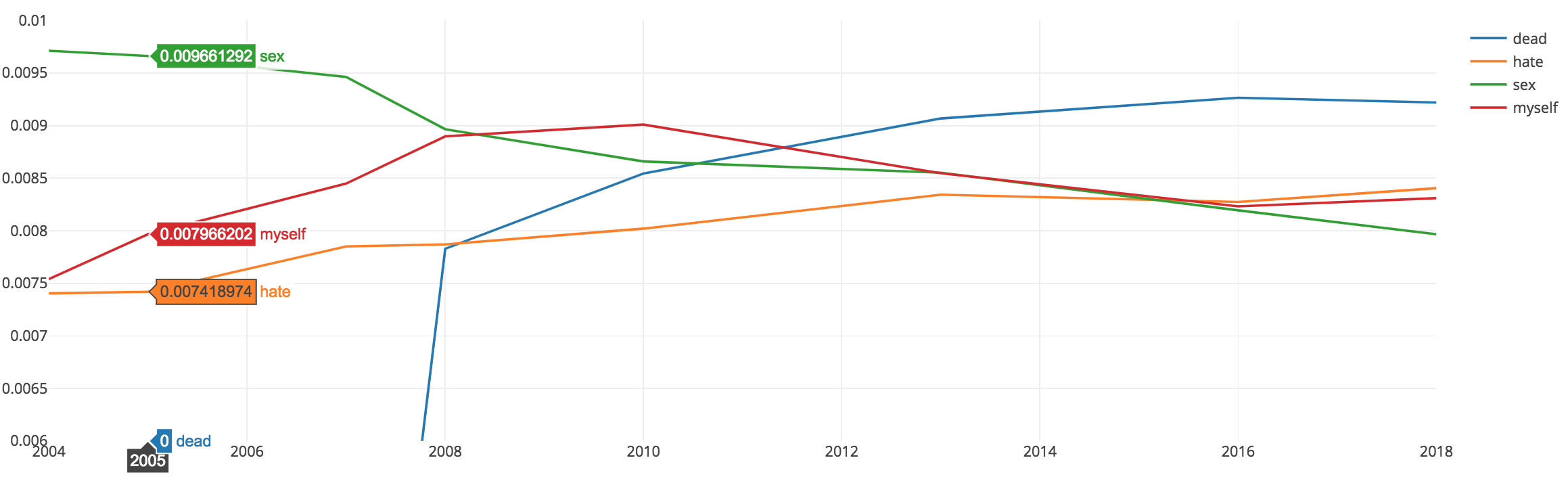
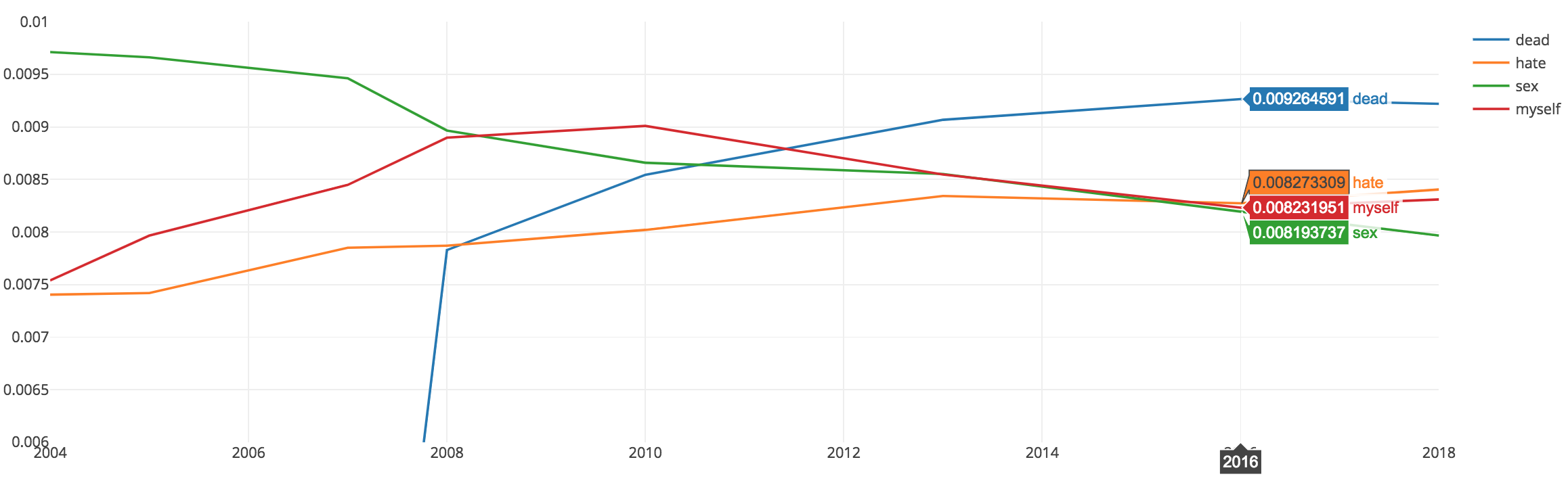
Conclusion
Machine Learning can provide powerful tools in the detection of changes
My analysis was an exploration into what was possible at the intersection of machine learning and mental health treatment. As I continue to learn and build on the skills I learn at General Assembly, I hope to be able to contribute more on topics that can have a positive impact on people’s lives. I am glad to see similar work being done in the field of data science and wanted to acknowledge the contributions currently being made by other individuals. To learn more, consider reading the article below:
MIT Technology Review: “your Tweets could show if you need help for bipolar disorder”
What we can discover can help the millions of people not only living with bipolar disorder but also their friends, families, coworkers, and the ones they love to manage an often misunderstood disorder.
Applied to mental health treatment
- Beyond Doctor Visits
- Provide an extension to treatment outside of in-person visits
- Real-Time Prognosis
- Independent evaluation that is less intrusive and provides benefit when actually needed
Takeaways
Using and collecting text data:
Model quality is tied directly to the quality of preprocessing data
Balancing manual text cleaning with scalable operations is extremely helpful
Building NLP models:
Topic Modeling can assist in finding overarching groups, flexible based on need (static vs dynamic)
Word2Vec creates reliable word association grouping and can be useful on larger corpus in NLP
To check out more about the project, visit the Github repo here.